
Introduction
Java is one of the most popular platforms available today. Despite its age (27 years old) it continues to offer one of the most performant runtime platforms available on the market. Its grammar can be perceived as verbose, its strongly typed nature difficult for newbies, but if you get past that you can leverage the JVM (Java Virtual Machine), a platform that:
- Constantly improves its efficiency and performance at runtime, thanks to continuous profiling and its multi-stage JIT compiler
- Is available on virtually all possible (server) hardware/architectures out there
- Has a strict “backwards compatibility contract”: the latest version of the JVM can still run bytecode compiled 27 years ago, at least in theory
- Has a vibrant community: you can always find an User Group (JUG) close to your location and leverage a huge ecosystem of OSS libraries/frameworks/applications
These factors have made Java one of the most used platforms in corporate environments, running applications in almost every sector. So, if you work for a big company, there’s a high chance that you are writing Java code or that you’re running your code on a JVM.
The Challenge with Serverless Functions
However, the very thing that makes the Java runtime so performant over time for server applications, the JIT compiler, is the reason why a Java program might be too slow to start in a Serverless environment.
The JVM needs to complete a warm-up phase where the bytecode is inspected multiple times, optimized, translated to hardware-specific instructions, and finally run.
This process might take seconds to complete, a very long time in the context of Microservices or Serverless functions.
AOT to the rescue?
There are ongoing efforts both within the JVM project (
Project Leyden
) and outside of it (
GraalVM
) having, among other goals, the purpose of addressing the startup times for short-lived processes, like Serverless functions.
GraalVM’s native-image can be already used today, as a stand-alone tool or using compatible frameworks such as
Quarkus
,
Spring
and others.
Problem solved? Yes, absolutely. If your stack is compatible with AOT and native image, by all means GO FOR IT.
But that’s not always the case. Let me clarify that with an example.
Hello, SOAP (JAX-WS) client
Let’s assume that:
- You work for a big company, with rules and processes in place concerning which technologies/libraries/frameworks can be used.
- You maintain a monolithic Java application Application A, whose code has been recently migrated to Java 11. This application is a billing system, which validates the VAT Numbers of EU-based commercial customers using the VIES SOAP WebService . The implementation is done using JAX-WS
- Application A is deployed on AWS
There is now another application being developed in your organization - Application B, a web shop - which needs to perform the same validation. In order to avoid increased traffic to Application A and to better handle sudden traffic spikes you decide to extract the logic and create an AWS Lambda function.
In this particular scenario, generating a native image can be really tricky so plain Java is the only viable option. We have to deal with cold starts on our own.
Note: This example is an abstraction of real experiences that I have while working for different customers at Claranet Switzerland (btw we're hiring !); what follows is my personal journey in analyzing “cold start” problems. I wanted to share it with you, and with my “future self”, in the hope it might be useful, and to get some feedback.
Default Corretto 11 runtime
Let’s start from the default runtime provided by AWS: Corretto 11
A first baseline test reveals the following average times with 512MB of allocated RAM:
- Init duration:
2.09s - Duration:
860ms
That’s unacceptable by modern standards, so let’s start reducing those times!
1. Optimize your code
Make sure to initialize expensive (thread-safe) resources outside the handleRequest method, in order to reuse resources for subsequent invocations
public class Handler implements RequestHandler<ValidationRequest, ValidationResponse> {
private static final Logger LOGGER = LoggerFactory.getLogger(Handler.class);
private static final CheckVatPortType PORT;
// initialize PORT in the static initializer
static {
var wsdlLocation = Thread.currentThread().getContextClassLoader()
.getResource("wsdl/checkVatService.wsdl");
var qName = new QName("urn:ec.europa.eu:taxud:vies:services:checkVat", "checkVatService");
PORT = new CheckVatService(wsdlLocation, qName).getCheckVatPort();
}
public Handler() {
}
@Metrics(captureColdStart = true)
@Tracing
@Override
public ValidationResponse handleRequest(ValidationRequest input, Context context) {
// validates input params and calls performValidation
}
@Tracing(segmentName = "Call remote webservice")
private static ValidationResponse performValidation(String country, String vatNumber) {
var valid = new Holder<Boolean>();
var name = new Holder<String>();
var address = new Holder<String>();
// PORT is already initialized
PORT.checkVat(
new Holder<>(country),
new Holder<>(vatNumber),
new Holder<>(),
valid,
name,
address
);
return new ValidationResponse(valid.value, name.value, address.value);
}
}
this won’t help with startup times, but it will be extremely useful for subsequent invocations of the same function.
2. Optimize your runtime
If your code is very simple (like the one above) you can decide to disable incremental JIT compilation, also known as Tiered Compilation. By doing so we instruct the JVM to ignore optimizations. The lambda will never reach peak performances at runtime, but at the same time we’ll get a quicker startup. This is a good compromise in this case, as the task is very simple and short-lived by design. Read the official AWS blog post for more information.
You can also decide to use the Serial Garbage Collector (SerialGC) instead of the default G1. Lambda functions are designed to be short-lived and single-threaded, so there’s no point in using a powerful Garbage Collector if your application is not supposed to be alive for more than a couple of minutes. More info on the official Java documentation
You can apply these modifications by adding the following environment variable in the lambda configuration:
JAVA_TOOL_OPTIONS="-XX:+TieredCompilation -XX:TieredStopAtLevel=1 -XX:+UseSerialGC"
3. Results
With all this optimization in place, we can now measure a cold start, sending the following test event to the lambda vies-proxy-11:
{
"country": "IE",
"vatNumber": "10000"
}
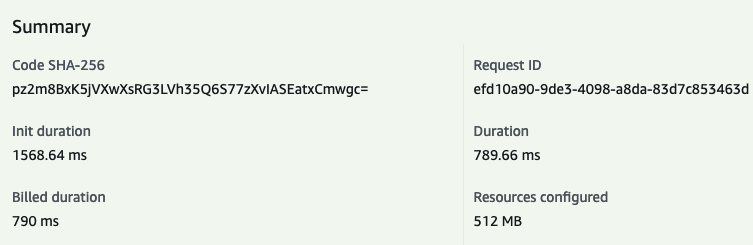
- Init duration:
1.57s - Duration:
800ms
Not that bad as starting point, considering that we have allocated just 512MB of RAM.
But we have to do better, since the lambda execution time will have a direct impact on the end-user experience.
JRE 19 (Docker runtime)
Recently the JVM dev team put a lot of effort into reducing startup time of Java programs, so it makes definitely sense to run our lambda with the latest (stable) runtime.
AWS Lambda supports running custom Docker images, so let’s go ahead and try to build a custom image.
You can find the full Dockerfile
here
.
1. Multi-stage is better
We’ll build a multi-stage Dockerfile. The resulting image will have fewer layers and therefore will be more compact in size, resulting in a reduced cold start.
2. Build a smaller JRE
JDK9 introduced jlink, a tool that allows us to build a smaller version of the JRE. We can include only the modules we need:
# Find JDK module dependencies dynamically from the uber jar
RUN jdeps -q \
--ignore-missing-deps \
--multi-release 19 \
--print-module-deps \
software/target/function.jar > /tmp/jre-deps.info
# Create a slim JRE which only contains the required modules to run the function
RUN jlink --verbose \
--compress 2 \
--strip-java-debug-attributes \
--no-header-files \
--no-man-pages \
--output /jre-slim \
--add-modules $(cat /tmp/jre-deps.info)
3. Use (App) Class-Data Sharing
Class-Data sharing (CDS)
Since version 12, the JVM ships with a pre-generated Shared Archive of system classes. This archive contains information ready to be used by the JVM, reducing CPU usage, memory usage, and startup time. Since we’ve generated a trimmed version of the JRE, we need to regenerate the Shared Archive:
# Generate CDS archive for our slim JRE
# It creates the file /jre-slim/lib/server/classes.jsa
RUN /jre-slim/bin/java -Xshare:dump -XX:+UseSerialGC -version
AppCDS
Since version 13 it’s possible to generate such archive also for the application code. Every millisecond counts for us, so we’ll do it:
RUN export AWS_LAMBDA_RUNTIME_API="localhost:8080" &&\
/jre-slim/bin/java --add-opens java.base/java.util=ALL-UNNAMED -XX:ArchiveClassesAtExit=appCds.jsa -jar function.jar "com.claranet.vies.proxy.Handler::handleRequest" 2>/dev/null 1>&2 || :
the process will exit with an error (ignored by the command), but the important thing for us is to process as many classes as we can.
4. Results
Let’s run the vies-proxy-19 function with the same payload as before
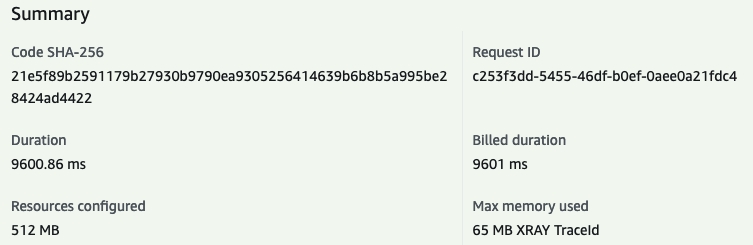
- Init duration (from Tracing) :
3.72s - Duration:
9.6s
wow, that’s disappointing.
However, further load testing resulted in faster average init times, especially when increasing the allocated RAM to 2048MB (which in turn increases the available
vCPUs
)
My guess is that the Docker image is somehow pulled and cached in a closer location when you start invoking your lambda multiple times.
You can see detailed results at the end of the post.
JRE 19 (custom runtime)
It is also possible to run our JRE 19 as a custom runtime. This will hopefully remove the overhead of pulling the Docker image when the host for our lambda changes.
We can reuse the instructions we already wrote in the Dockerfile to build the custom runtime. See https://github.com/claranet-ch/java-lambda-optimization/blob/main/infrastructure/src/main/java/com/claranet/vies/proxy/stack/ViesProxyStack.java#L79-L105
Custom runtimes are only available on
x86_64CPU architecture
Results
Let’s run the vies-proxy-19-custom function with the same payload:
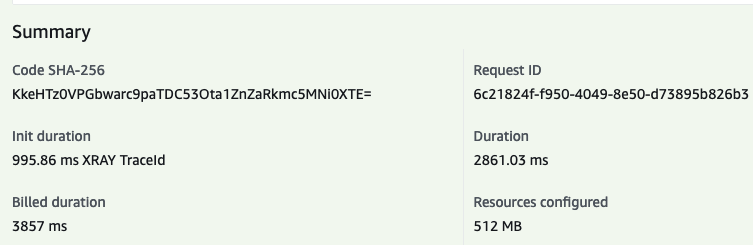
- Init duration (from Tracing) :
996ms - Duration:
2.8s
Eureka! We’ve got sub-second cold start! 🎉
For the record, increasing the allocated RAM to 2048MB we get:
- Init duration (from Tracing) :
852ms - Duration:
972ms
Way better, but maybe we can try a new approach to reduce startup times even more.
AWS SnapStart
Very recently, AWS announced SnapStart at re:Invent.
SnapStart is a new deployment process that starts up the micro-container running the function, waits for its initialization, and then performs a snapshot of its state. When the lambda function is invoked, SnapStart will restore the already initialized snapshot instead of initializing the JVM again.
SnapStart is only available for x86_64 CPU architecture and might not be compatible with your code. Please check https://docs.aws.amazon.com/lambda/latest/dg/snapstart.html for additional information
1. Application initialization
Since we have the opportunity to start our lambda before taking the snapshot, we can manage to fully initialize the SOAP client before the snapshot is taken, in order to reduce the application initialization time.
What is this application initialization time?
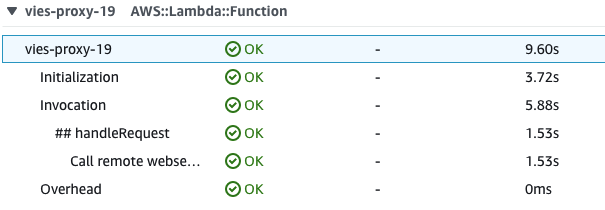
Let’s take a closer look at the tracing for the latest invocation of vies-proxy-19-custom:
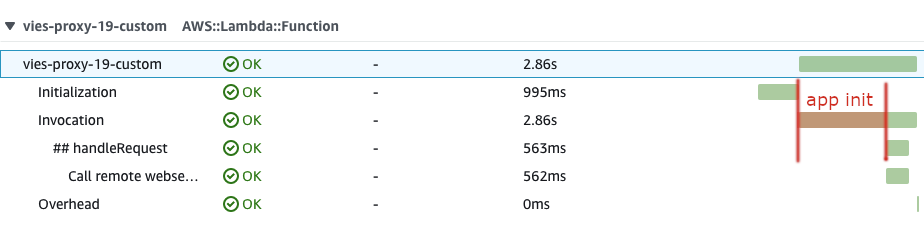
Application initialization is everything happening between “Initialization” (cold start) and “## handleRequest”. That’s more than 2s (2.86 - 0.563) in the screenshot!
For example, this might be related with the SOAP client initialization and all the dynamic proxies it generates to perform the request and parse the response.
Let’s modify the code to try to include these objects in the snapshot as well.
2. Lifecycle hooks
SnapStart supports CRaC checkpoint API, so we can modify the Lambda Handler to simulate a request before the snapshot happens:
// [...]
import org.crac.Core;
import org.crac.Resource;
// [...]
public class Handler implements RequestHandler<ValidationRequest, ValidationResponse>, Resource { // <-- implements org.crac.Resource
public Handler() {
Core.getGlobalContext().register(this); // <-- register snapshot listener
}
// [...]
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) {
// as per https://docs.aws.amazon.com/lambda/latest/dg/snapstart-runtime-hooks.html SnapStart supports CRaC hooks.
// We use that to load as many objects as we can in memory before performing the checkpoint,
// in order to prevent expensive initializations from happening at runtime
performValidation("IE", "123456"); // <-- forces SOAP client initialization
}
@Override
public void afterRestore(org.crac.Context<? extends Resource> context) {
LOGGER.info("Restore complete");
}
}
full source code available here
3. Results
After enabling SnapStart and publishing a new version, let’s run our usual test:
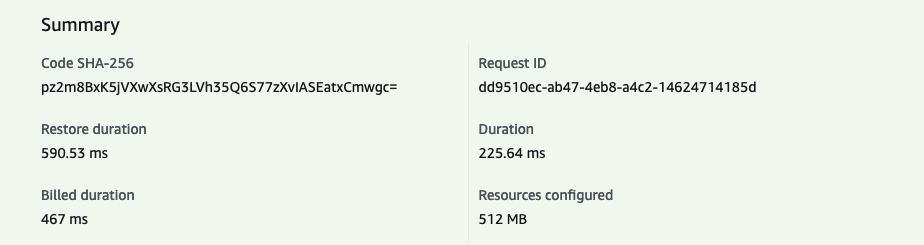
- Restore duration :
591ms - Duration:
226ms
Sub-second response time! Outstanding! 🎉
For reference, not optimized code (i.e. without snapshot listener) results in a faster restore time but slower response time overall:
- Restore duration :
331ms - Duration:
614ms
While increasing allocated RAM to 2048MB results in:
- Restore duration :
275ms(most likely due to the increased I/O and CPU resources) - Duration:
238ms
Comparing results
I have run a benchmark using a new feature of AWS Lambda Power Tuning which hasn’t been released yet, and then collected the resulting times using Logs Insights . Will do an additional blog post to explain this process soon. Stay tuned 😅
Here are the resulting times:
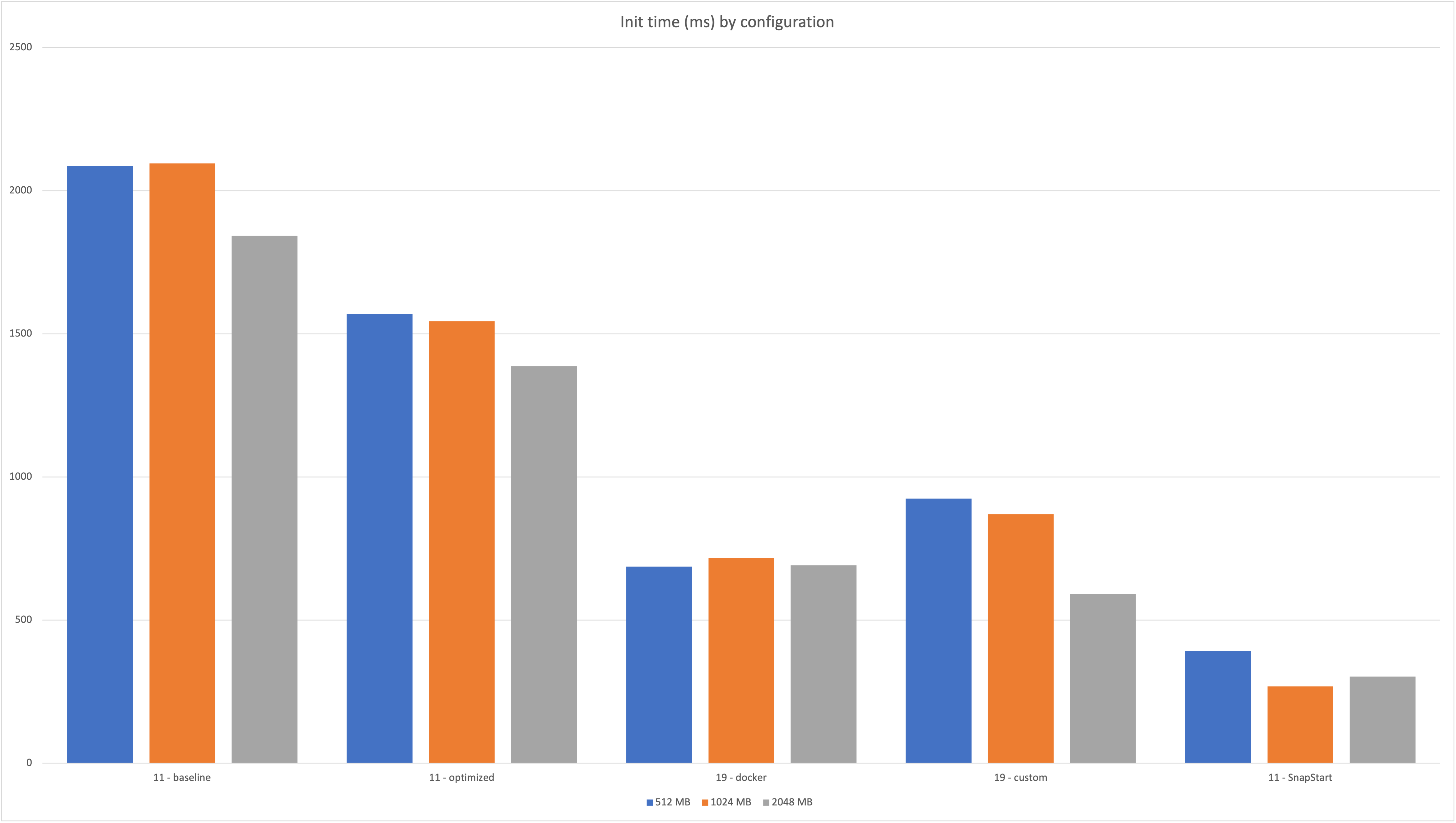
More info, including queries to retrieve data, can be found in this spreadsheet
Conclusion
Cold start can be really an issue for user-facing Java serverless functions. There are some promising technologies which you can already use, but they cannot work in all cases.
If you can go native using AOT and GraalVM, then GO FOR IT, as it is probably the best available option right now.
If you can’t, the best option right now is SnapStart. But it comes with constraints and limitations.
In any case I hope that this post can give you some hints and a blueprint for a process you can follow. If you want to experiment yourself with the code, you can find it here: https://github.com/claranet-ch/java-lambda-optimization